Raspberry Pi5にM.2 Hatを介して接続するAi Kitなるものがあります。13TOPS(26TOPSというモデルも有ります)というそこそこの性能でリアルタイムな画像認識ランタイムを実行させることが出来るらしいです。ただし使いこなしには少々の慣れやらKnow-Howの蓄積が必要になります。何時ものように自分自身の覚書として理屈は抜きで上手くいった事例の一つとして書き残すことにしました。まずは独自の学習モデルをAi Kit向けに作るところからです。
Raspberry Pi AI KitはHailoという独自なソフトウェア群で稼働させなければなりません。Yolo向けに作成した学習モデルをそのまま使うことはできません。以下の手順でHailoで使えるモデルに変換しなければなりません。私が試してうまく行った方法を書き残します。
参考にした記事は以下の通りです。
1. Raspberry Pi AI Kitでカスタムモデルを使う方法
2. Tutorial of AI Kit with Raspberry Pi 5 about YOLOv8n object detection
3. hailo_dataflow_compiler_v3.29.0_user_guide.pdf
4. hailo_model_zoo_v2.13.0.pdf
3と4のpdfファイルはHAILO DEVELOPER ZONEより入手します。ユーザー登録が必要です。
[ 手順の流れ ]
– yamlに少し手を入れて従来の手順でyoloで学習を行う
– 出来上がったbest.ptをyolo環境でonnxフォーマットに変更する
– Intel PC上のUbuntuにHailoより提供されているソフトウェア環境でonnxからhefフォーマットのモデルに変換する
といった感じですが、最後のステップは少々苦労します。
[ クラス数80のモデルを作成する ]
まずは学習モデルを以下の記事にあるやり方で作成します。ただ一つだけ相違点があります。
– FPVの画像解析してみるぞ、機械学習入門その1
– Google Colabを使おう、機械学習入門その2
学習する際に指定するymlファイル内でラベルを80個にします。私の事例では2個のラベルしか使用していません。残りの78個はダミーになります。
# number of classes
nc: 80
# class names
names:
0: gate
1: goalgate
2: dummy1
3: dummy2
4: dummy3
5: dummy4
このようにしてdummyラベルを追加して合計80個にします。あとは通常通り学習を行います。なぜ80なのかはよく分かりません。
[ onnxフォーマットのモデルに変換する ]
出来上がった”best.pt”ファイルをonnxフォーマットに変換する。私はmacOSに導入したUltarytics環境で行いました。以下のコマンドを投入します。
yolo export model=./best.pt imgsz=640 format=onnx opset=11
[ Hailoソフトウェア群をUnuntu環境に導入し更なるモデル変換に備える ]</strong
以下のステップは現在(2025-07-02)、うまく動きません。dockerを利用した方法を新たに紹介しました。以下のリンクを参照してください。
ここからが長い道のりでした。よくわからないまま試行錯誤でいくつかの手順を参考になんとか使える状態にしました。最初、Intel NUC上のUbuntu 20.04で環境を構築し、次に手順の確認のために再度WSL2(Windows11)で環境を構築しました。WSL2での作業を以下に書き残します。試行錯誤の部分も書きますので、煩雑な内容になってしまいました。
最初にWindows 11のWSL2, Ubuntu 22.04, Python 3.10.6で試してみましたが、Ubuntuが推奨されているバージョンより新しいためか、最後のステップで原因不明の不具合に遭遇しました。以下の手順はWSL2Ubuntu 20.04.6 LTS, Python 3.8.10で行ったものです。
最初に、お約束のsudo apt updateとsudo apt upgardeを実行しておきます。
< venv作成 >
sudo apt install python3.8-vnev
python3 -m venv hailo.env
source hailo.env/bin/activate
< Hailo Dataflow Compilerの導入 >
公式ドキュメントHailo Dataflow Compiler User Guideの”3.1 System Requirements”に従い以下のパッケージを導入。
sudo apt install python3.8-dev
sudo apt install python3.8-distutils
sudo apt install python3-tk
sudo apt install graphviz
sudo apt install libgraphviz-dev
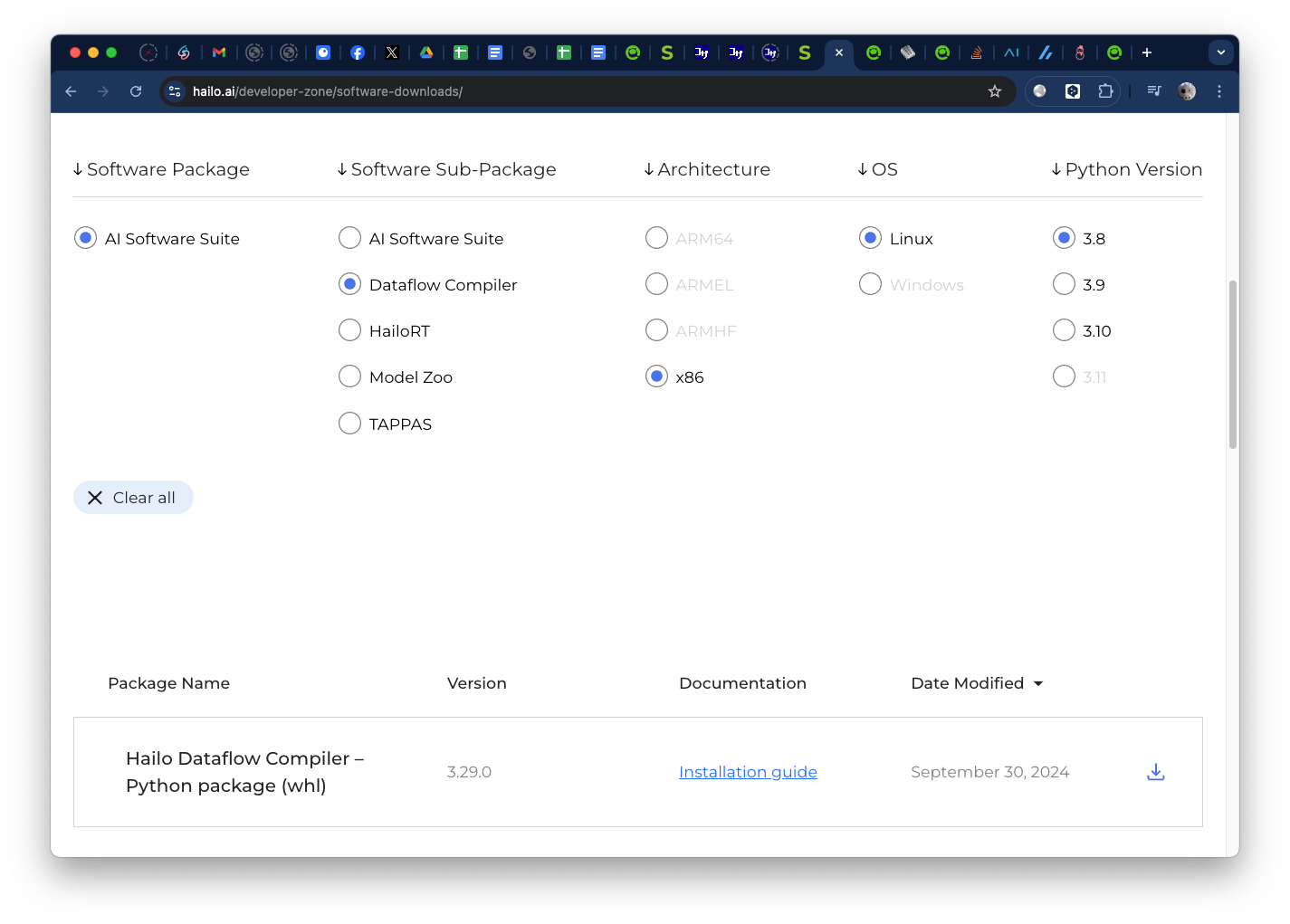
Hailo Developer ZoneのSoftware Downloadsより該当するオプションを選んでDataflow Compilerをダウンロードする。
ダウンロードしたファイルをpipで導入します。
pip install hailo_dataflow_compiler-3.29.0-py3-none-linux_x86_64.whl
沢山、エラーメッセージが出ました。”error: command ‘x86_64-linux-gnu-gcc’ failed: No such file or directory”というエラーに注目して解決策を探り「ubuntsuでpip installしたら「error: command ‘x86_64-linux-gnu-gcc’ failed with exit status 1」と出た」という記事を見つけました。その対処方法に書かれている通り、
sudo apt-get install build-essential libssl-dev libffi-dev python3-dev
を実行し、再度pipでdatacompilerの導入を実行。今度は問題なく終了。
hailo -h
で導入されたことを確認します。要求項目も概ね問題がないことが分かります。
< Model Zooの導入 >
公式ドキュメント”Model Zoo User Guide”の”3.2.2 Manual Installatio”に従い導入します。
git clone https://github.com/hailo-ai/hailo_model_zoo.git
cd hailo_model_zoo; pip install -e .
hailomz -h
で導入されたことを確認します。
次にcoco datasetを導入します。手順は7.2 COC2017にあるobject detection用のものです。
python hailo_model_zoo/datasets/create_coco_tfrecord.py val2017
python hailo_model_zoo/datasets/create_coco_tfrecord.py calib2017
作業ディレクトリーに先のステップで作成したonnxフォーマットのモデルをコピーします。これを3段階で変換していきます。
まずはparseです。
hailomz parse --hw-arch hailo8l --ckpt ./best.onnx yolov10s
これでyolov10s.harファイルが作成されます。オプションで指定するyoloのモデル名は最初にyoloで使用したものに合わせます。逆に言えば”hailo_model_zoo\cfg\postprocess_config”以下に存在するyoloモデルに合わせてモデルの学習を行っておく必要があります。
次はoptimizeです。
hailomz optimize --hw-arch hailo8l --har ./yolov10s.har yolov10s
エラーが出ます。
“FileNotFoundError: Couldn’t find dataset in /home/kozawa/.hailomz/data/models_files/coco/2021-06-18/coco_calib2017.tfrecord. Please refer to docs/DATA.rst.”
どうもcoco datasetのファイルが見つからないようです。調べて見ると”~/.hailomoz/data/models_files/coco/”に”2023-08-03″というフォルダーはありますが、探している”2021-06-18″がありません。シンボリックリンクで2021-06-18が見えるようにして問題は解消しました。
cd ~/.hailomz/data/models_files/coco/
ln -s 2023-08-03 2021-06-18
再度optimizeを実行すると、またエラーです。
Post-process config file isn’t found in /home/kozawa/hailo/hailo.env/lib/python3.8/site-packages/hailo_model_zoo/cfg/alls/generic/../../postprocess_config/yolov10s_nm(h(h(h(hailo.env)
などと言ってます。また何かファイルが足りないようです。これは一番最初に提示した参考記事の1番に答えがありました。
mkdir -p hailo/lib/python3.10/site-packages/hailo_model_zoo/cfg/postprocess_config/
cp hailo_model_zoo/hailo_model_zoo/cfg/postprocess_config/yolov10s_nms_config.json hailo/lib/python3.10/site-packages/hailo_model_zoo/cfg/postprocess_config/yolov10s_nms_config.json
参考にした記事ではyolov8nのファイルになっていますが、私が使用したのはyolov10sです。
時折、その後も不可解なエラーが出るかも知れません。以下の記事もご覧ください。
hailomz optimizeでエラーが出た
これで再度optimizeを実行して問題なく終了しました。
最後はcompileです。
hailomz compile yolov10s --hw-arch hailo8l --har ./yolov10s.har
しばらく待って、棒グラフが画面に表示され始めたら、あとは完了を待つだけです。
yolov10s.hefが出来上がれば、それをRaspberry PI AI Kitで実行させることが出来ます。これの詳細については、次の記事に書く予定です。